Machine learning is niet meer weg te denken uit moderne software applicaties. Computers worden steeds slimmer en kunnen steeds beter voorspellingen maken, en machine learning (samen met kunstmatige intelligentie) heeft daar een groot aandeel in. Een simpel voorbeeld zijn de aanbevelingen die een dienst als Netflix geeft op basis van je kijkgeschiedenis. In dit artikel zoomen we in op de verschillende aspecten van machine learning en de werking daarvan. Ook kijken we naar een relatief simpele toepassing van de techniek.
Geschreven door Jaap Slootbeek (Developer), Kevin te Raa (Developer) en Bart Wesselink (Head of Development).
Het begrip machine learning kent vele definities. In de basis komt het neer op computers die steeds slimmer worden op basis van informatie uit het verleden. Een machine learning probleem kent in feite drie ingrediënten:
Bij machine learning is het de bedoeling dat de computer steeds beter wordt op basis van de ervaring die het heeft en de feedback (in de vorm van performance) die het krijgt. Daar waar traditioneel gezien de computer een input krijgt in combinatie met een programma, waaruit dan een output komt, krijgt een machine learning probleem juist input en output, en komt daar een programma uit.
Er zijn verschillende soorten problemen die machine learning kan oplossen. We beginnen bij regressie. In de basis is een regressieprobleem het voorspellen van de toekomst, op basis van het verleden. Er wordt een zogeheten wiskundig model gezocht dat zo goed mogelijk past op basis van data uit het verleden. Of een model goed past kan op verschillende manieren gecontroleerd worden, bijvoorbeeld door te kijken naar de som van alle fouten. In de afbeelding hiernaast staat een grafiek waarbij er met een willekeurige lijn begonnen wordt, en deze wordt aangepast op basis van de som van alle fouten. Uiteindelijk komt er een lijn uit die ongeveer in het midden van alle punten ligt.
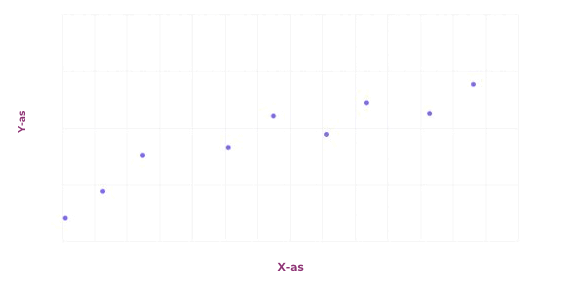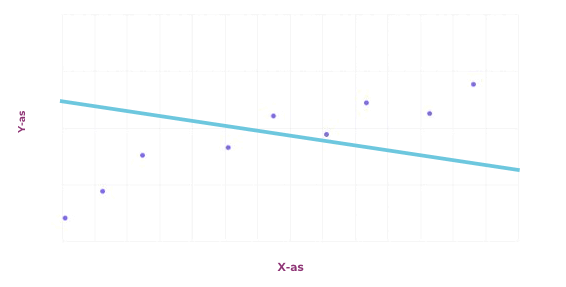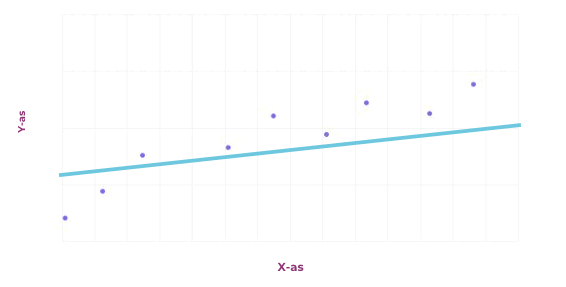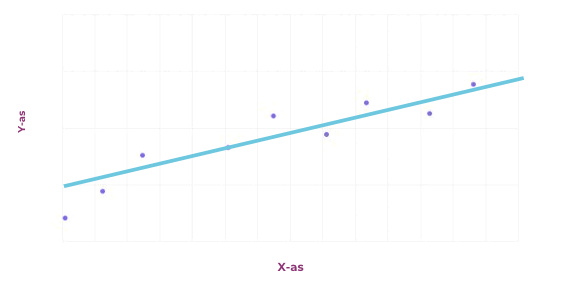
Een andere opdracht kan zijn om data te classificeren, bijvoorbeeld afbeeldingen. Alle inputs krijgen dan een bepaald label toegewezen, en de bedoeling is om een model te maken dat dit label kan voorspellen op basis van aspecten van de input. Deze voorspelling wordt meestal gegeven in de vorm van een percentage. Dat percentage staat voor hoe zeker het model is over het toegewezen label.
Het is belangrijk dat een model ook gevalideerd wordt op een andere dataset dan waarop het getraind is. Vaak wordt er daarom gekozen om een dataset op te splitsen in training- en testdata. Het model wordt dan gemaakt op basis van de trainingsdata, waarna de test data gebruikt wordt om te kijken hoe goed het model werkt op nieuwe gegevens. Dit is belangrijk, omdat een model zich anders te veel focust op de trainingsdata, en slecht werkt in andere omstandigheden.
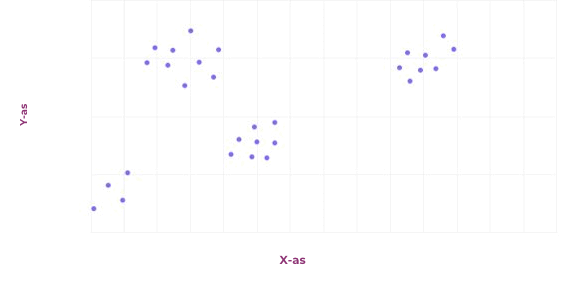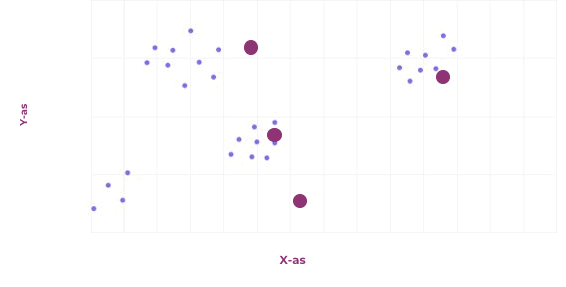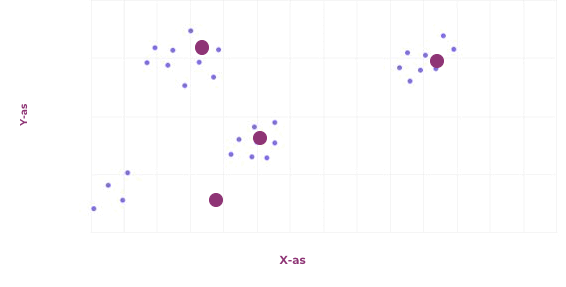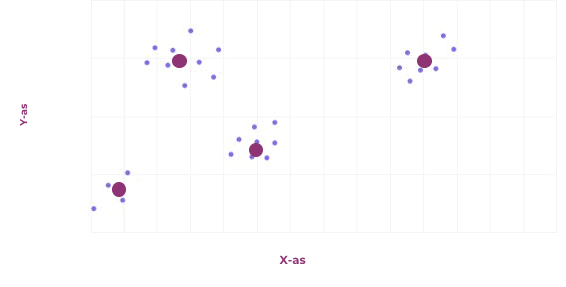
Het laatste probleem dat we in dit artikel behandelen is clustering. Het doel van clusteren is om veel voorkomende patronen in data te ontdekken, en deze te groeperen. Eén van de vele algoritmes om dit te doen, is door te beginnen met willekeurige clusters. Alle punten wijs je daarna toe aan het dichtstbijzijnde cluster, waarna het middelpunt van alle punten die toegewezen zijn aan een specifiek cluster het nieuwe cluster wordt. Dit herhaal je net zo lang totdat er weinig tot niets meer veranderd. Een voorbeeld is weergegeven in de afbeelding hiernaast.
Een veelgebruikte use case voor machine learning is het aanbevelen van items op basis van de interesses van mensen. Denk daarbij aan het aanraden van films op basis van de kijkgeschiedenis van een gebruiker, of het aanbevelen van nieuwe producten op basis van eerdere bestellingen. Volgens onderzoek door Kumar en Hosanagar uit 2018 kan een goed aanbevelingssysteem op webshops voor een gemiddelde verkoopstijging van 11% zorgen. Het idee bij een aanbevelingssysteem is dat de interesses van een persoon worden vergeleken met iemand anders die vergelijkbare interesses heeft, geheel anoniem.
Er zijn veel verschillende manieren om tot een aanbeveling te komen. In dit artikel behandelen we een relatief simpele manier aan de hand van een simpele producten verkoopt. De eerste stap begint bij het verzamelen van data. Voor alle productenparen gaan we kijken hoeveel mensen zowel product A en ook product B gekocht hebben, en zetten dit in een tabel (een matrix). Voor alle cellen in de tabel bepalen we dan de zogeheten Log-Likelihood Ratio. Deze ratio bepaalt de mate waarin product A en product B samen vaker voorkomen dan je zou verwachten, puur afgaande op kans. Uiteindelijk kunnen de waardes die daar uitkomen gebruikt worden om te kijken wat vele voorkomende combinaties zijn. Deze combinaties kunnen dan aan een gebruiker getoond worden.
Binnen Recognize hebben we onze eigen systemen om toepassingen te realiseren die aanbevelingen kunnen doen op basis van anonieme data. We denken dan ook graag met je mee naar hoe deze techniek binnen jouw bedrijf ingezet kan worden.
Benieuwd naar voorbeelden? Of heb je zelf een toepassing voor machine learning? Neem contact met ons op!
Benieuwd naar wat we voor jou kunnen betekenen? Of kun je iets voor ons betekenen? Dan horen we graag van je! Bel of mail gerust. We komen graag langs om kennis te maken. En natuurlijk staan onze deuren op de zevende verdieping van de Javatoren in Almelo ook altijd voor je open.


